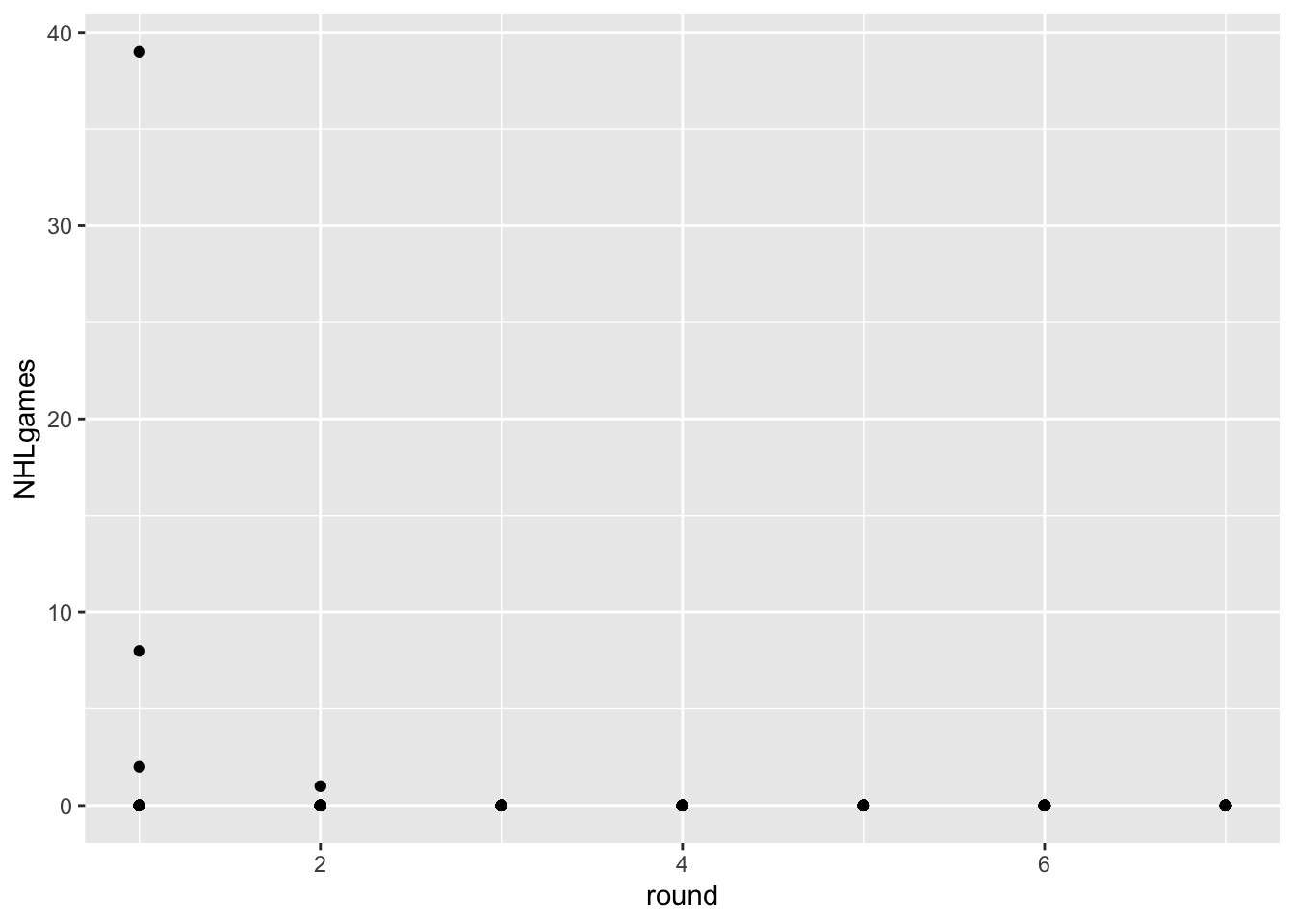
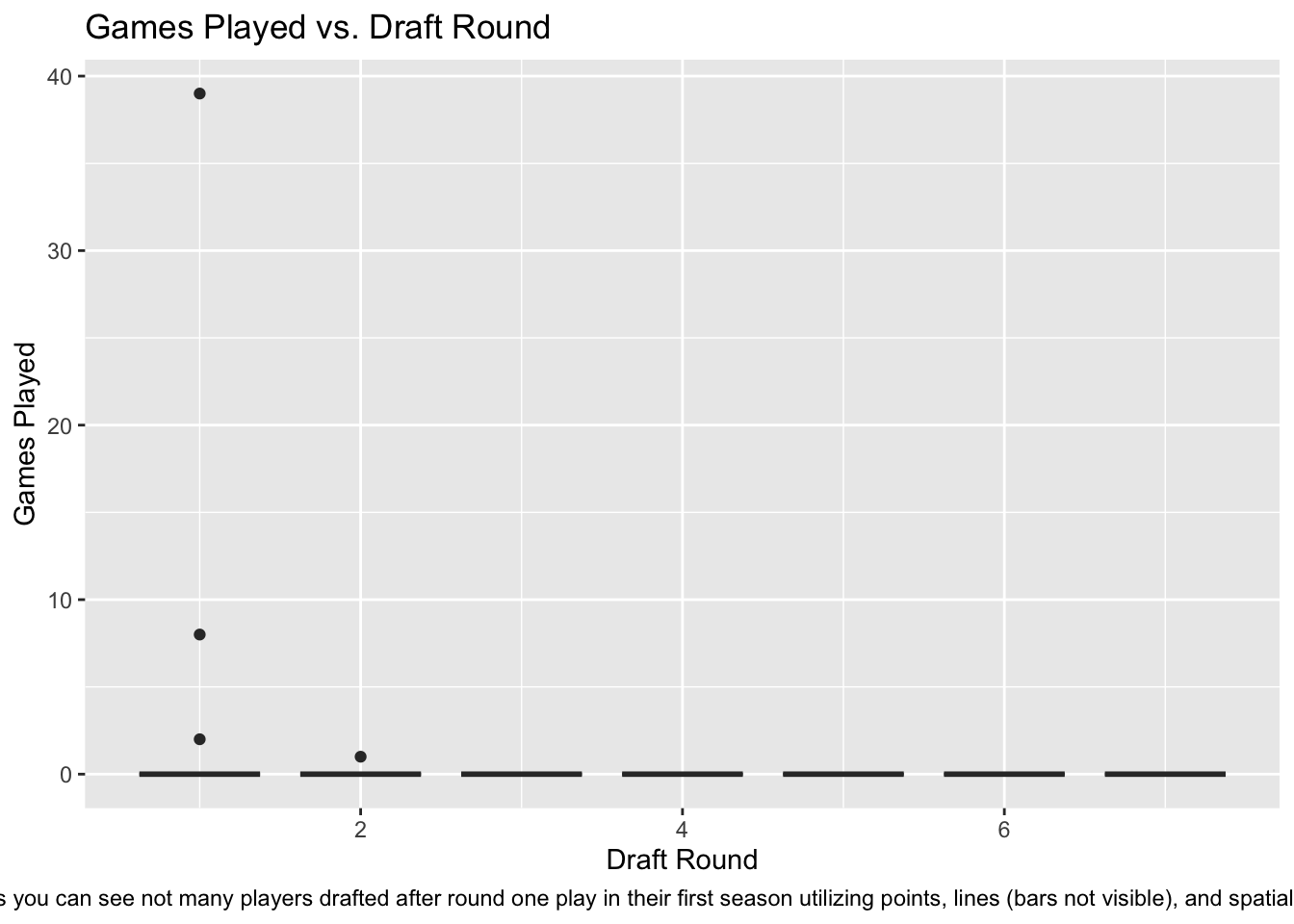
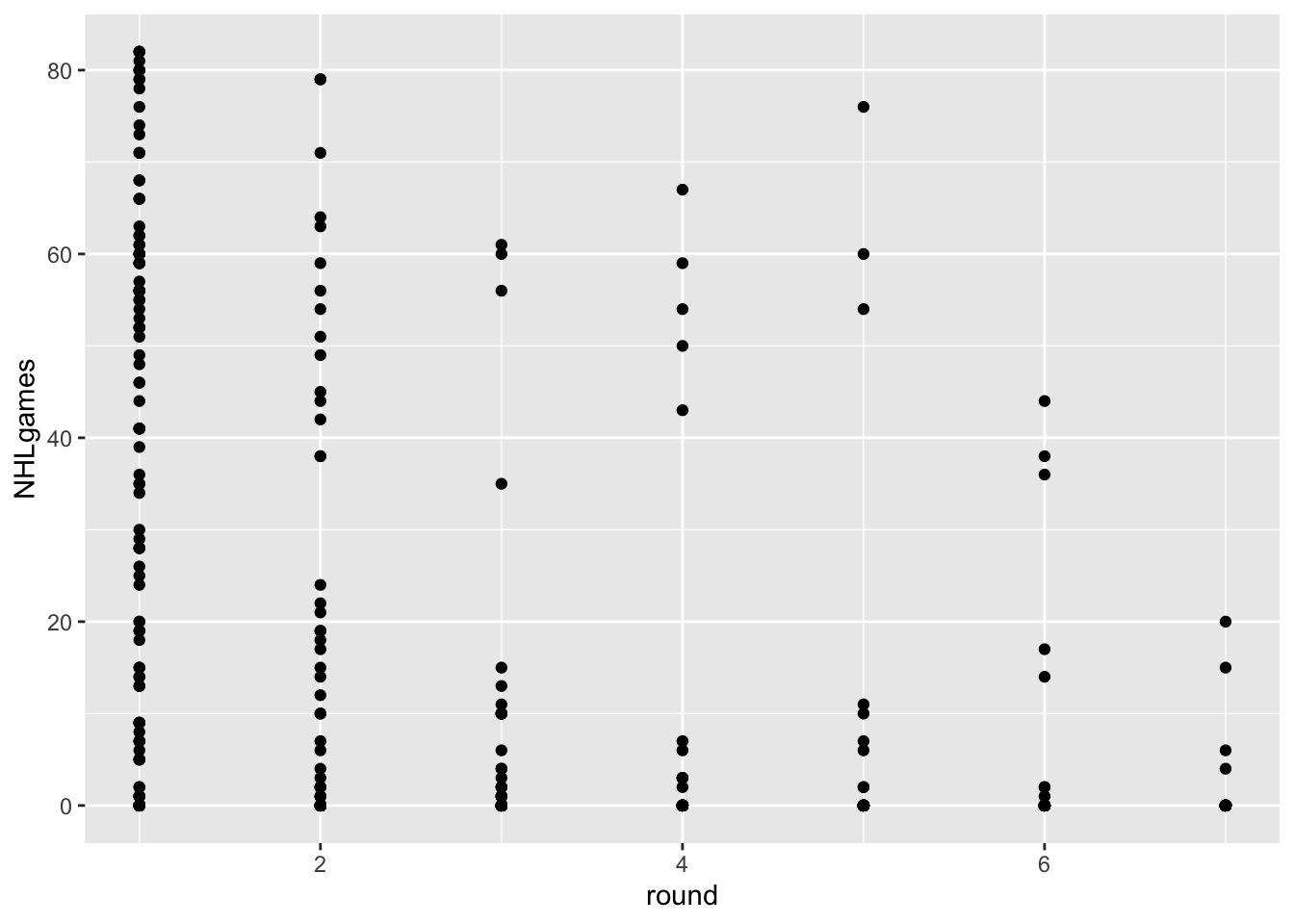
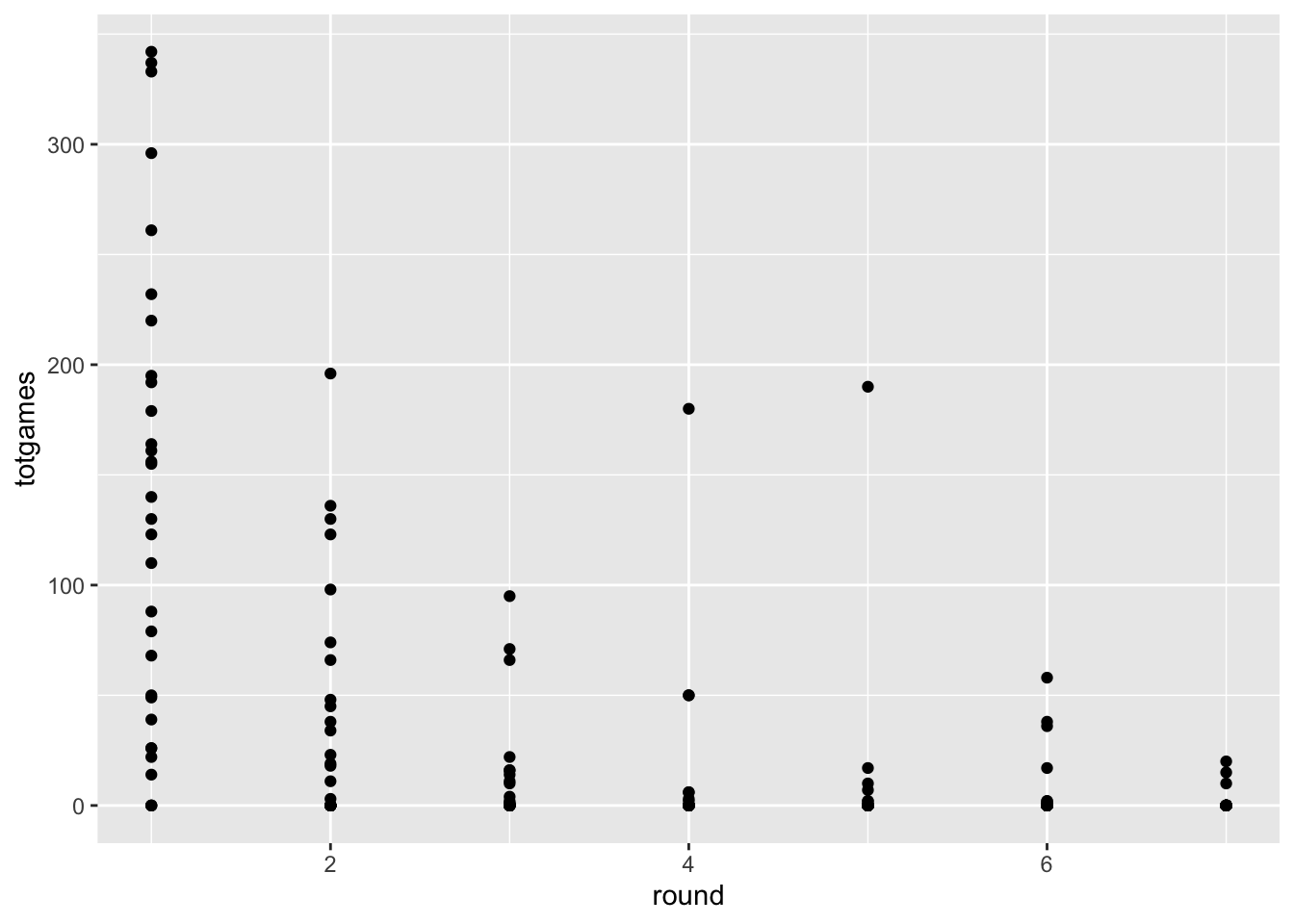
Code
library(tidyverse)── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.0 ✔ purrr 1.0.1
✔ tibble 3.1.8 ✔ dplyr 1.0.10
✔ tidyr 1.2.1 ✔ stringr 1.5.0
✔ readr 2.1.3 ✔ forcats 0.5.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()Code
library(dplyr)
library(ggplot2)
library(readxl)
NHLDraft<-read.csv("NHLDraft.csv")
NHLDictionary<-read_excel("NHLDictionary.xlsx")
glimpse(NHLDraft)Rows: 105,936
Columns: 12
$ X <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ draftyear <int> 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001…
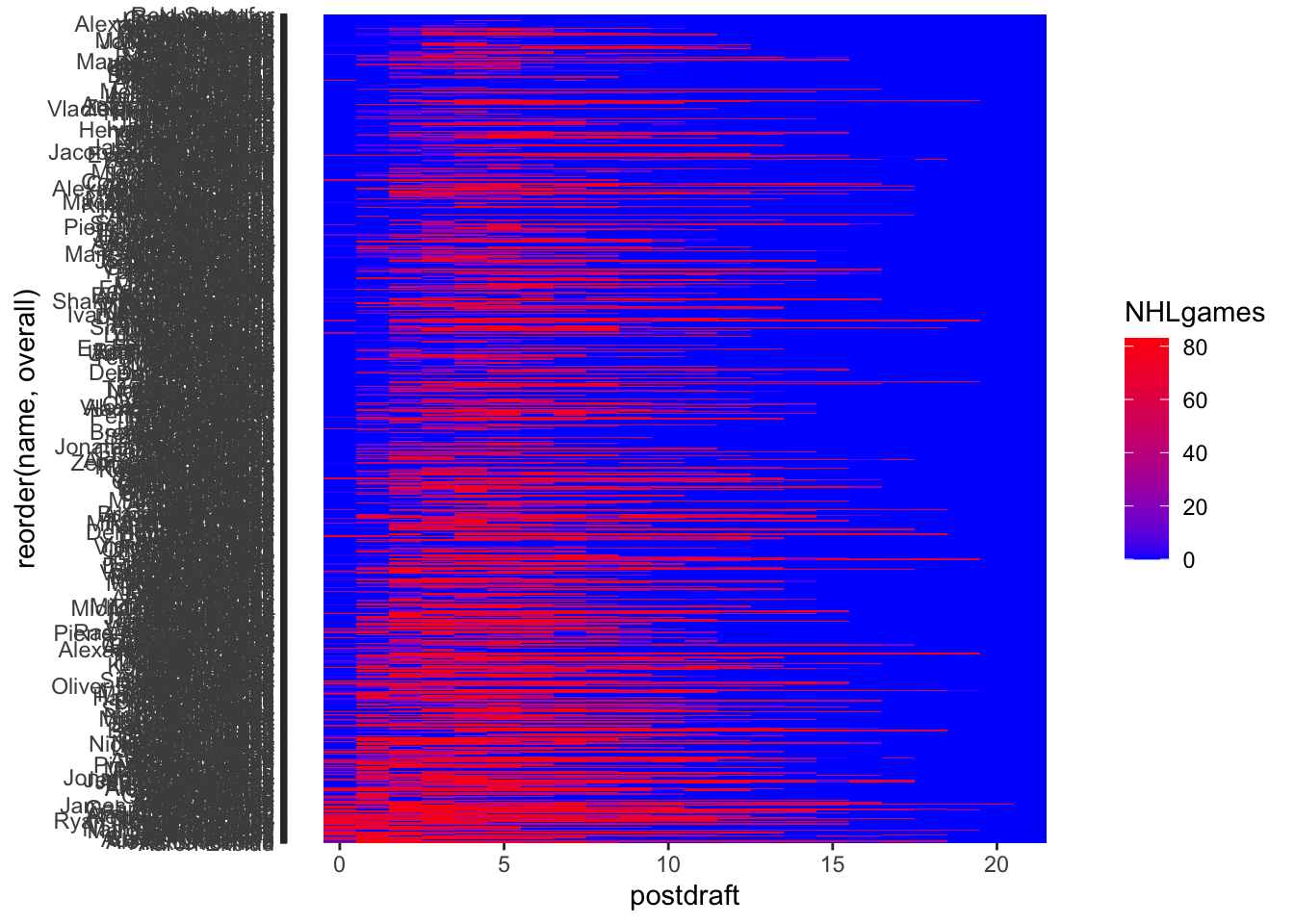
$ name <chr> "Drew Fata", "Drew Fata", "Drew Fata", "Drew Fata", "Drew …
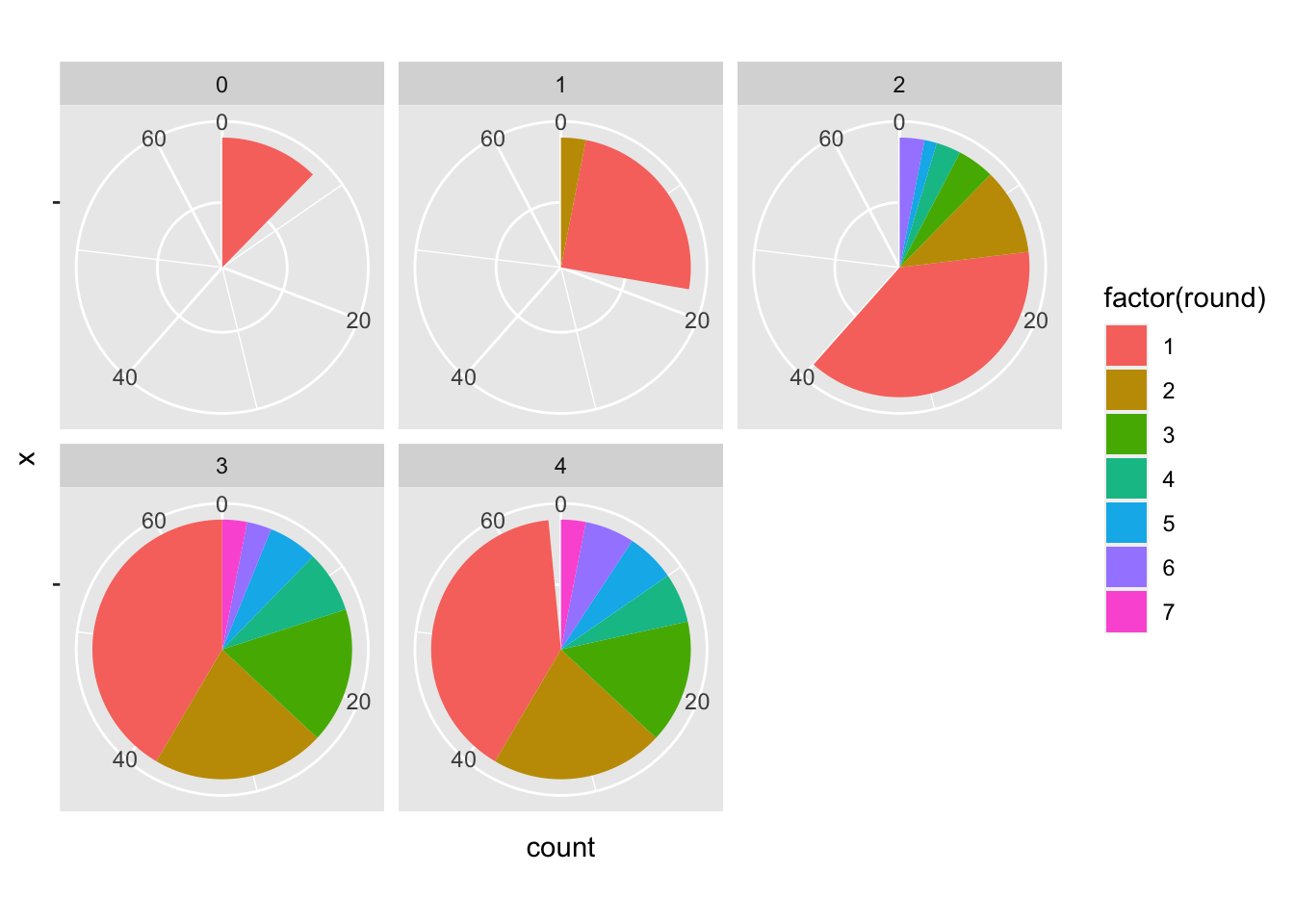
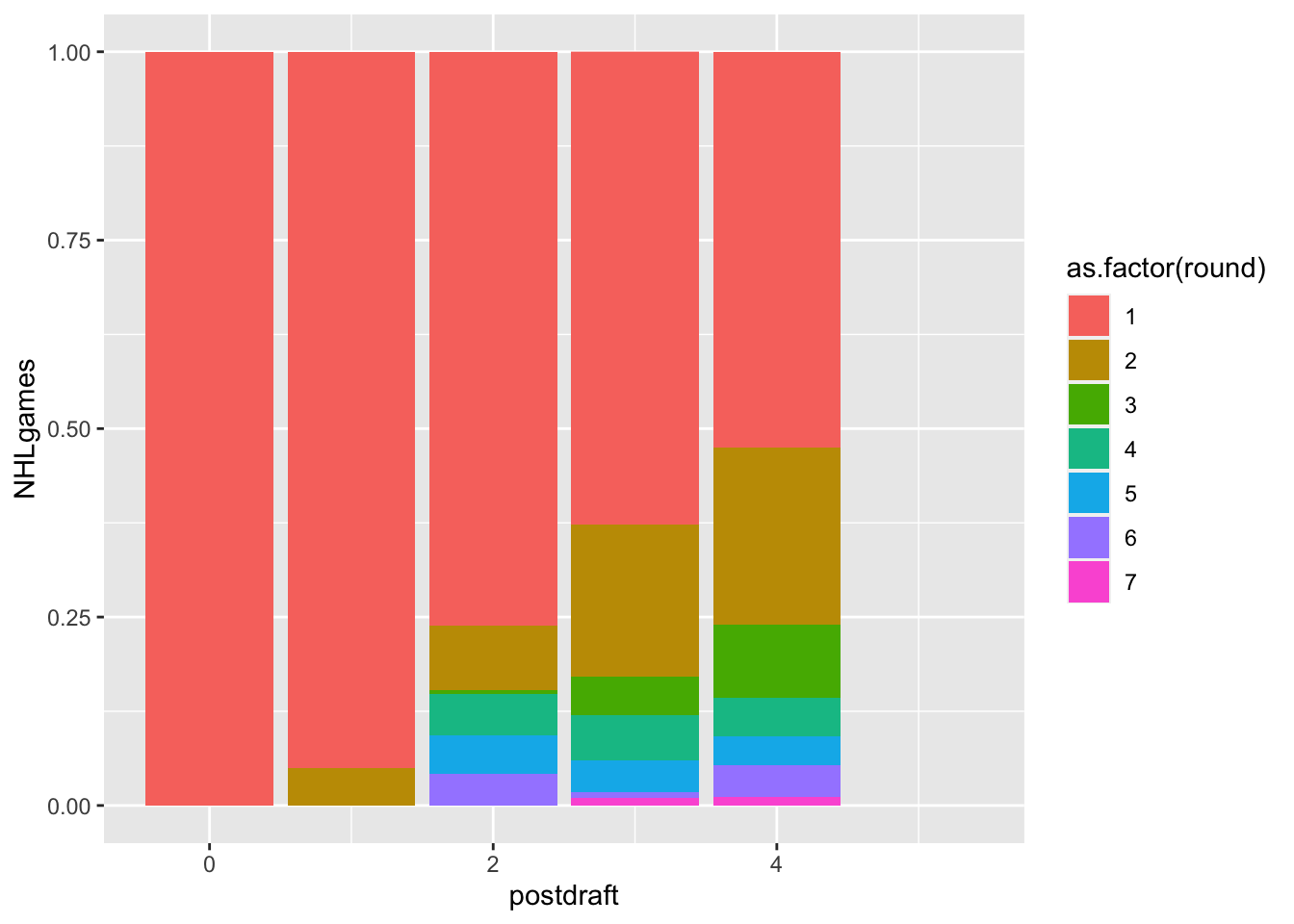
$ round <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
$ overall <int> 86, 86, 86, 86, 86, 86, 86, 86, 86, 86, 86, 86, 86, 86, 86…
$ pickinRound <int> 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23…
$ height <int> 73, 73, 73, 73, 73, 73, 73, 73, 73, 73, 73, 73, 73, 73, 73…
$ weight <int> 209, 209, 209, 209, 209, 209, 209, 209, 209, 209, 209, 209…
$ position <chr> "Defense", "Defense", "Defense", "Defense", "Defense", "De…
$ playerId <int> 8469535, 8469535, 8469535, 8469535, 8469535, 8469535, 8469…
$ postdraft <int> 0, 1, 2, 4, 5, 10, 11, 12, 13, 3, 6, 7, 8, 9, 14, 15, 16, …
$ NHLgames <int> 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0…Code
knitr::kable(NHLDictionary)| Attribute | Type | Description |
|---|---|---|
| draftyear | Ordinal | Calendar year in which the player was drafted into the NHL. |
| name | Item | Full name of the player. |
| round | Ordinal | Round in which the player was drafted (1 to 7). |
| overall | Ordinal | Overall draft position of the player (1 to 224) |
| pickinRound | Ordinal | Position in which the player was drafted in their round (1 to 32). |
| height | Quantitative | Player height in inches. |
| weight | Quantitative | Player weight in pounds. |
| position | Categorical | Player position (Forward, Defense, Goaltender) |
| playerId | Item | Unique ID (key) assigned to each player. |
| postdraft | Ordinal | Number of seasons since being drafted (0 to 20). |
| NHLgames | Quantitative | Number of games played in the NHL in that particular season (regular season is 82 games, playoffs are up to 28 more). |